Data Science students are always looking for new and interesting datasets to train machine learning models. There’s tons of public data out there. Unfortunately, in the US, many of our "public" datasets are difficult to access. The most interesting data is hidden behind dark patterns on corporate and government websites.
Here you’ll see how to use Pandas to easily pull down a lot of data from prosocial websites like wikipedia. Then you’ll learn a little BeautifulSoup to scrape out that sneaky data that hides behind dark patterns.
pandas.read_html
If you build web pages with tables in them, they become accessible to anybody who knows how to use Pandas, like this Wikipedia page:
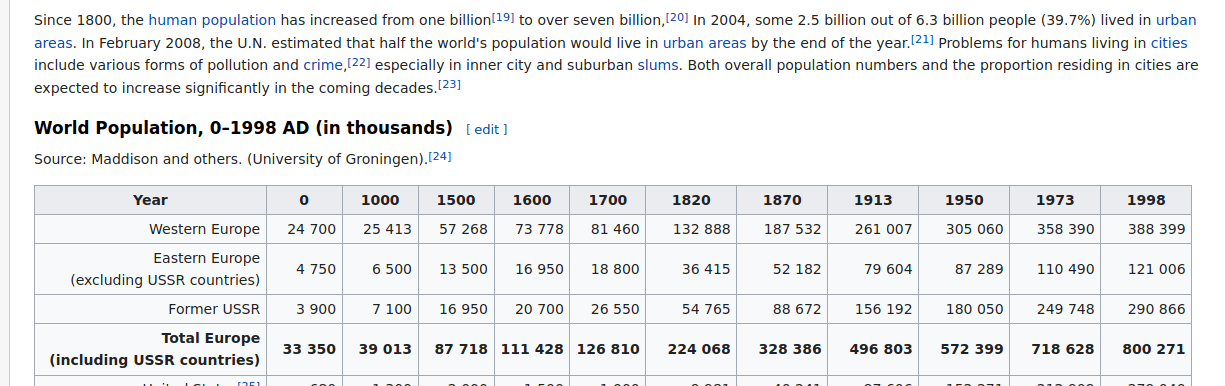
>>> import pandas as pd
>>> base_url = 'https://en.wikipedia.org'
>>> page_title = 'demographics of the world'
>>> page_url = f'{base_url}/wiki/{page_title.replace(" ", "_")}'
>>> tables = pd.read_html(page_url)
>>> len(tables)
25Then you can easily find the interesting tables and calculate some statistics:
>>> for df in tables:
... if len(df) > 10 and len(df.describe().columns) > 1:
... print('='*70)
... print(df.describe(include='all'))
... print('='*70)
... print()Here’s one of those tables of descriptive statistics:
================================================================================================================================================================
Year 0 1000 1500 1600 1700 1820 1870 1913 1950 1973 1998
count 17 17.000000 17.000000 17.000000 17.000000 17.000000 17.000000 17.000000 17.000000 17.000000 17.000000 17.000000
unique 17 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
top United States NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
freq 1 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
mean NaN 17.158824 16.752941 16.829412 16.858824 16.788235 17.064706 17.064706 17.064706 16.911765 16.905882 16.758824
std NaN 28.360008 26.822684 26.260849 26.968131 26.524938 27.237197 25.845767 24.935666 24.582257 24.890397 25.281887
min NaN 0.200000 0.200000 0.200000 0.100000 0.100000 0.100000 0.500000 0.800000 0.900000 1.000000 0.900000
25% NaN 1.300000 2.400000 2.300000 1.100000 1.300000 1.400000 3.100000 4.400000 5.400000 5.400000 4.600000
50% NaN 2.400000 4.200000 4.000000 3.700000 4.500000 5.300000 7.000000 7.000000 7.100000 7.900000 6.900000
75% NaN 15.900000 15.400000 20.100000 20.000000 21.000000 20.100000 19.900000 17.000000 15.500000 17.300000 16.500000
max NaN 100.000000 100.000000 100.000000 100.000000 100.000000 100.000000 100.000000 100.000000 100.000000 100.000000 100.000000
================================================================================================================================================================Dark Patterns
What’s a dark pattern? It’s any UX that prevents people from getting things done without manipulation and distraction and lock-in. For a Data Scientist a dark pattern prevents them from accessing data.
When the Internet was new, and only teenagers and geeks knew how to use it, public officials could be forgiven for "publishing" data in PDFs or proprietary spreadsheets and databases. But we live in an era where elected officials responsible for securing voter registration data have the skill to deploy dark pattern websites that support their political agenda. And the skill to do this sort of sophisticated technical work is not limited to advanced, stable democracies like the United States. Officials in charge of data in most developing countries are also deploying sophisticated web applications that breach the public trust. Do a Duck search for "Brian Kemp suppression" if you want to learn more. He was so adept at managing his IT department, he successfully made voter registration data accessible only to his supporters and campaign managers. And using predictive analytics on this data, he was able to delete the voter registrations for those that would likely vote against him in his campaign for Governor.
Illuminating the Dark
So I’ll show you how easy it is to process data from prosocial public data sources like Wikipedia. And then I’ll show you the problem with some dark patterns on the web. Some are intentional and some are not, but we’ll help you illuminate the data you want and scrape it.
There are no options for the pd.read_html function that do what you want. So when I tried to get a list of business names from the California Department of State website, I get everything except the name when Pandas automatically parses the HTML:
>>> import pandas as pd
>>> bizname = 'poss'
>>> url = f'https://businesssearch.sos.ca.gov/CBS/SearchResults?filing=&SearchType=CORP&SearchCriteria={bizname}&SearchSubType=Begins'
>>> df = pd.read_html(url)[0]
>>> df
Entity Number Registration Date Status Entity Name Jurisdiction Agent for Service of Process
0 C2645412 04 / 02 / 2004 ACTIVE View details for entity number 02645412 POSSU... GEORGIA ERESIDENTAGENT, INC. (C2702827)
1 C0786330 09 / 22 / 1976 DISSOLVED View details for entity number 00786330 POSSU... CALIFORNIA I. HALPERN
2 C2334141 03 / 01 / 2001 FTB SUSPENDED View details for entity number 02334141 POSSU... CALIFORNIA CLAIR G BURRILL
3 C0658630 11 / 08 / 1972 FTB SUSPENDED View details for entity number 00658630 POSSU... CALIFORNIA NaN
4 C1713121 09 / 23 / 1992 FTB SUSPENDED View details for entity number 01713121 POSSU... CALIFORNIA LAWRENCE J. TURNER
5 C1207820 08 / 05 / 1983 DISSOLVED View details for entity number 01207820 POSSU... CALIFORNIA R L CARL
6 C3921531 06 / 27 / 2016 ACTIVE View details for entity number 03921531 POSSU... CALIFORNIA REGISTERED AGENTS INC(C3365816)The website hides business names behind a button. But you can use requests to download the raw html. Then you can use bs4 to extract the raw HTML table as well as any particular row(< tr >) or cell(< td >) that you want.
First lets see how public APIs and the semantic web are supposed to work. Say I read a great SciFi novel, Three Body Problem and wanted to find other books that, like it, won the Hugo Award for best novel. This is how you search for something on wikipedia:
>>> import requests
>>> base_url = 'https://en.wikipedia.org'
>>> search_text = 'hugo award best novel liu'
>>> search_results = requests.get(
... 'https://en.wikipedia.org/w/index.php',
... {'search': search_text},
... )
>>> search_results
<Response [200]>Now we can programmatically find the page with the Hugo Awards using BeautifulSoup4. Don’t try to install BeautifulSoup without tacking on that version 4 to the end. Otherwise you’ll get some confusing error messages. And the import name is bs4, not beautifulsoup. The .find() method finds the first element in a BeautifulSoup object. So if you want to walk through the list of search result, use .findall().
You only need the first search result for this carefully crafted search; ):
>>> import bs4
>>> soup = bs4.BeautifulSoup(search_results.text)
>>> soup.find('div', {'class': 'searchresults'})
>>> soup = (soup.find('div', {'class': 'searchresults'}) or soup).find('ul')
>>> hugo_url = (soup.find('li') or soup).find('a', href = True).get('href')
>>> hugo_url
'/wiki/Hugo_Award_for_Best_Novel'So now we can join the wikipedia path with the base_url to get to the page containing the data table we’re looking for. And we can use Pandas to deal download and parse it directly, without any fancy BeaufulSouping.
Some of this code is on stack overflow in the answer to["Pandas read_html to return raw HTML"](https: // stackoverflow.com / a / 65755142 / 623735).
>>> soup = bs4.BeautifulSoup(requests.get(url).text)
>>> table = soup.find('table').findAll('tr')
>>> names = []
... for row in table:
... names.append(getattr(row.find('button'), 'contents', [''])[0].strip())
>>> names[-7:]
['POSSUM FILMS, INC',
'POSSUM INC.',
'POSSUM MEDIA, INC.',
'POSSUM POINT PRODUCTIONS, INC.',
'POSSUM PRODUCTIONS, INC.',
'POSSUM-BILITY EXPRESS, INCORPORATED',
'POSSUMS WELCOME']Now you can replace that useless column with the correct Button Text, the names of the businesses we’re interested in. You need to ignore the first row in the HTML table, because it contains the header "Entity Name" and does not have a button tag:
>>> df['Entity Name'] = names[1:]
>>> df.tail()
Entity Number Registration Date Status Entity Name Jurisdiction Agent for Service of Process
96 C2334141 03/01/2001 FTB SUSPENDED POSSUM MEDIA, INC. CALIFORNIA CLAIR G BURRILL
97 C0658630 11/08/1972 FTB SUSPENDED POSSUM POINT PRODUCTIONS... CALIFORNIA NaN
98 C1713121 09/23/1992 FTB SUSPENDED POSSUM PRODUCTIONS, INC. CALIFORNIA LAWRENCE J. TURNER
99 C1207820 08/05/1983 DISSOLVED POSSUM-BILITY EXPRESS, I... CALIFORNIA R L CARL
100 C3921531 06/27/2016 ACTIVE POSSUMS WELCOME CALIFORNIA REGISTERED AGENTS INC (C...Resources
If you’re working on an NLP problem, you can get data from Wikipedia the propper way… with a database dump: TDS Post on working with Wikipedia data dumps
Hacker Public Radio is awesome! I’m going to try to record my first podcast today, based on this blog post. I’ll share these ideas for scraping public data out through the holes in dark patterns with Python (Pandas, Beautiful Soup). It’ll be good practice for the monthly meetup
San Diego Python User Group.
