Making an intelligent chatbot has never been easier, thanks to the abundance of open source natural language processing libraries, curated datasets and the power of transfer learning. Building a basic question-answering functionality with Transformers library can be as simple as this:
Input 1: Load Pretrained Transformer QA Model
from transformers import pipeline# Context: a snippet from a Wikipedia article about Stan Leecontext =""" Stan Lee[1] (born Stanley Martin Lieber /ˈliːbər/; December 28, 1922 - November 12, 2018) was an American comic book writer, editor, publisher, and producer. He rose through the ranks of a family-run business to become Marvel Comics' primary creative leader for two decades, leading its expansion from a small division of a publishing house to multimedia corporation that dominated the comics industry. """nlp = pipeline('question-answering')result = nlp(context=context, question="Who is Stan Lee?")"""
Output 1: Report for Default Transformer QA Model
{'score': 0.2854291316652837,'start': 95,'end': 159,'answer': 'an American comic book writer, editor, publisher, and producer.'}
BOOM! It works! That low confidence score is a little worrisome, though. You’ll see how that comes into play later, when we talk about BERT’s ability to detect impossible questions and irrelevant contexts.
However, taking some time to choose the right model for your task will ensure that you are getting the best possible out of the box performance from your conversational agent. Your choice of both language models and a benchmarking dataset will make or break the performance of your chatbot.
BERT (Bidirectional Encoding Representations for Transformers) models perform very well on complex information extraction tasks. They can capture not only meaning of words, but also the context. Before choosing model (or settling for the default option) you probably want to evaluate your candidate model for accuracy and resources (RAM and CPU cycles) to make sure that it actually meets your expectations. In this article you will see how we benchmarked our qa model using Stanford Question Answering Dataset (SQuAD). There are many other good question-answering datasets you might want to use, including Microsoft’s NewsQA, CommonsenseQA, ComplexWebQA, and many others. To maximize accuracy for your application you’ll want to choose a benchmarking dataset representative of the questions, answers, and contexts you expect in your application.
Huggingface Transformers library has a large catalogue of pretrained models for a variety of tasks: sentiment analysis, text summarization, paraphrasing, and, of course, question answering. We chose a few candidate question-answering models from the repository of available models. Lo and behold, many of them have already been fine-tuned on the SQuAD dataset. Awesome! Here are a few SQuAD fine-tuned models we are going to evaluate:
We ran predictions with our selected models on both versions of SQuAD (version 1 and version 2). The difference between them is that SQuAD-v1 contains only answerable questions, while SQuAD-v2 contains unanswerable questions as well. To illustrate this, let us look at the below example from the SQuAD-v2 dataset. An answer to Question 2 is impossible to derive from the given context from Wikipedia:
Question 1: “In what country is Normandy located?”
Question 2: “Who gave their name to Normandy in the 1000’s and 1100’s”
Context: “The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (“Norman” comes from “Norseman”) raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.”
Our ideal model should be able to understand that context well enough to compose an answer.
Let us get started!
To define a model and a tokenizer in Transformers, we can use AutoClasses. In most cases Automodels can derive the settings automatically from the model name. We need only a few lines of code to set it up:
Input 2: Load Large Uncased BERT Transformer Pretuned for SQuAD
We will use the human level performance as our target for accuracy. SQuAD leaderboard provides human level performance for this task, which is 87% accuracy of finding the exact answer and 89% f1 score.
You might ask, “How do they know what human performance is?” and “What humans are they talking about?” Those Stanford researchers are clever. They just used the same crowd-sourced humans that labeled the SQuAD dataset. For each question in the test set they had multiple humans provide alternative answers. For the human score they just left one of those answers out and checked to see if it matched any of the others using the same text comparison algorithm that they used to evaluate the machine model. The average accuracy for this “leave one human out” dataset is what determined the human level score that the machines are shooting for.
To run predictions on our datasets, first we have to transform the SQuAD downloaded files into computer-interpretable features. Luckily, the Transformers library already has a handy set of functions to do exactly that:
Input 3: Load and Preprocess SQuAD v2
from transformers import squad_convert_examples_to_featuresfrom transformers.data.processors.squad import SquadV2Processorprocessor = SquadV2Processor()examples = processor.get_dev_examples(path)features, dataset = squad_convert_examples_to_features( examples=examples, tokenizer=tokenizer, max_seq_length=512, doc_stride =128, max_query_length=256, is_training=False, return_dataset='pt', threads=4, # number of CPU cores to use)
We will use PyTorch and its GPU capability (optional) to make predictions:
Input 4: Prediction (Inference) with a Transformer
import torchfrom torch.utils.data import DataLoader, SequentialSamplereval_sampler = SequentialSampler(dataset)eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=10)all_results = []def to_list(tensor):return tensor.detach().cpu().tolist()for batch in tqdm(eval_dataloader): model.eval() batch =tuple(t.to(device) for t in batch)with torch.no_grad(): inputs = {"input_ids": batch[0],"attention_mask": batch[1],"token_type_ids": batch[2], # NOTE: skip token_type_ids for distilbert } example_indices = batch[3] outputs = model(**inputs) # this is where the magic happensfor i, example_index inenumerate(example_indices): eval_feature = features[example_index.item()] unique_id =int(eval_feature.unique_id)
Importantly, the model inputs should be adjusted for a DistilBERT model (such as distilbert-base-cased-distilled-squad). We should exclude the “token_type_ids” field due to the difference in DistilBERT implementation compared to BERT or ALBERT to avoid the script erroring out. Everything else will stay exactly the same.
Finally, to evaluate the results, we can apply squad_evaluate() function from Transformers library:
Input 5: transformers.squad_evaluate()
from transformers.data.metrics.squad_metrics import squad_evaluateresults = squad_evaluate(examples, predictions, no_answer_probs=null_odds)
Here is an example report generated by squad_evaluate:
Output 5: Accuracy Report from transformers.squad_evaluate()
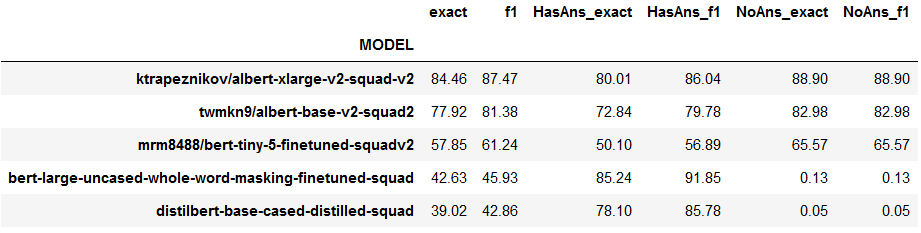
Now let us compare exact answer accuracy scores (“exact”) and f1 scores for the predictions generated for our two benchmarking datasets, SQuAD-v1 and SQuAD-v2. All models perform substantially better on the dataset without negatives (SQuAD-v1), but we do have a clear winner (ktrapeznikov/albert-xlarge-v2-squad-v2). Overall, it performs better on both datasets. Another great news is that our generated report for this model matches exactly the report posted by the author. The accuracy and f1 fall just a little short of the human level performance, but is still a great result for a challenging dataset like SQuAD.Table 1: Accuracy Scores for Each of 5 Models on SQuAD v1 & v2
We are going to compare the full reports for SQuAD-v2 predictions in the next table. Looks like ktrapeznikov/albert-xlarge-v2-squad-v2 did almost equally well on both tasks: (1) identifying the correct answers to the answerable questions, and (2) weeding out the answerable questions. Interestingly though, bert-large-uncased-whole-word-masking-finetuned-squad offers a significant (approximately 5%) boost to the prediction accuracy on the first task (answerable questions), but completely failing on the second task.
Table 2: Separate Accuracy Scores for Impossible Questions
We can optimize the model to perform better on identifying unanswerable questions by adjusting the null threshold for the best f1 score. Remember, the best f1 threshold is one of the outputs computed by the squad_evaluate function (best_f1_thresh). Here is how the prediction metrics for SQuAD-v2 change when we apply the best_f1_thresh from the SQuAD-v2 report:
Input 6: Accuracy Report from transformers.squad_evaluate()
Table 3: Adjusted Accuracy Scores
While this adjustment helps the model more accurately identify the unanswerable questions, it does so at the expense of the accuracy of answered questions. This trade-off should be carefully considered in the context of your application.
Let’s use the Transformers QA pipeline to test drive the three best models with a few questions of our own. We picked the following the following passage from a Wikipedia article on computational linguistics:
Input 7: Computational Linguistics Questions (an unseen test example)
context ='''Computational linguistics is often grouped within the field of artificial intelligence but was present before the development of artificial intelligence.Computational linguistics originated with efforts in the United States in the 1950s to use computers to automatically translate texts from foreign languages, particularly Russian scientific journals, into English.[3] Since computers can make arithmetic (systematic) calculations much faster and more accurately than humans, it was thought to be only a short matter of time before they could also begin to process language.[4] Computational and quantitative methods are also used historically in the attempted reconstruction of earlier forms of modern languages and sub-grouping modern languages into language families.Earlier methods, such as lexicostatistics and glottochronology, have been proven to be premature and inaccurate. However, recent interdisciplinary studies that borrow concepts from biological studies, especially gene mapping, have proved to produce more sophisticated analytical tools and more reliable results.[5]'''questions=['When was computational linguistics invented?','Which problems computational linguistics is trying to solve?','Which methods existed before the emergence of computational linguistics ?','Who invented computational linguistics?','Who invented gene mapping?']
Note that the last two questions are impossible to answer from the given context. Here is what we got from each model we tested:
Output 7: Computational Linguistics Questions (last two are impossible questions)
Model: bert-large-uncased-whole-word-masking-finetuned-squad-----------------Question: When was computational linguistics invented?Answer: 1950s (confidence score 0.7105585285134239)Question: Which problems computational linguistics is trying to solve?Answer: earlier forms of modern languages and sub-grouping modern languages into language families. (confidence score 0.034796690637104444)Question: What methods existed before the emergence of computational linguistics?Answer: lexicostatistics and glottochronology, (confidence score 0.8949566496998465)Question: Who invented computational linguistics?Answer: United States (confidence score 0.5333964470000865)Question: Who invented gene mapping?Answer: biological studies, (confidence score 0.02638426599066701)Model: ktrapeznikov/albert-xlarge-v2-squad-v2-----------------Question: When was computational linguistics invented?Answer: 1950s (confidence score 0.6412413898187204)Question: Which problems computational linguistics is trying to solve?Answer: translate texts from foreign languages, (confidence score 0.1307672173261354)Question: What methods existed before the emergence of computational linguistics?Answer: (confidence score 0.6308010582306451)Question: Who invented computational linguistics?Answer: (confidence score 0.9748902345310917)Question: Who invented gene mapping?Answer: (confidence score 0.9988990117797236)Model: mrm8488/bert-tiny-5-finetuned-squadv2-----------------Question: When was computational linguistics invented?Answer: 1950s (confidence score 0.5100432430158293)Question: Which problems computational linguistics is trying to solve?Answer: artificial intelligence. (confidence score 0.03275686739784334)Question: What methods existed before the emergence of computational linguistics?Answer: (confidence score 0.06689302592967117)Question: Who invented computational linguistics?Answer: (confidence score 0.05630986208743849)Question: Who invented gene mapping?Answer: (confidence score 0.8440988190788303)Model: twmkn9/albert-base-v2-squad2-----------------Question: When was computational linguistics invented?Answer: 1950s (confidence score 0.630521506320747)Question: Which problems computational linguistics is trying to solve?Answer: (confidence score 0.5901262729978356)Question: What methods existed before the emergence of computational linguistics?Answer: (confidence score 0.2787252009804586)Question: Who invented computational linguistics?Answer: (confidence score 0.9395531361082305)Question: Who invented gene mapping?Answer: (confidence score 0.9998772777192002)Model: distilbert-base-cased-distilled-squad-----------------Question: When was computational linguistics invented?Answer: 1950s (confidence score 0.7759537003546768)Question: Which problems computational linguistics is trying to solve?Answer: gene mapping, (confidence score 0.4235580072416312)Question: What methods existed before the emergence of computational linguistics?Answer: lexicostatistics and glottochronology, (confidence score 0.8573431178602817)Question: Who invented computational linguistics?Answer: computers (confidence score 0.7313878935375229)Question: Who invented gene mapping?Answer: biological studies, (confidence score 0.4788379586462099)
As you can see, it is hard to evaluate a model based on a single data point, since the results are all over the map. While each model gave the correct answer to the first question (“When was computational linguistics invented?”), the other questions proved to be more difficult. This means that even our best model probably should be fine-tuned again on a custom dataset to improve further.
Take away:
Open source pretrained (and fine-tuned!) models can kickstart your natural language processing project.
Before anything else, try to reproduce the original results reported by the author, if available.
Benchmark your models for accuracy. Even models fine-tuned on the exact same dataset can perform very differently.
Leave a comment or send me an e-mail if I can help you get started with pretrained transformers!
Leave a comment or send me an e-mail if I can help you get started with pretrained transformers!
About The Author
Olesya Bondarenko is Lead Developer at Tangible AI where she leads the effort to make QAry smarter. QAry is an open source question answering system you can trust with your most private data and questions.